


Table of contents
Outline
The main idea inferred in this paper is by simple data augmentation the efficiency of a model (can we just maximize the rewards).
This method was to counterbalance the current issues in RL; i.e.; data-efficiency of learning and generalization to a new environment. With all the previous data augmentation techniques "Random translate" for image-based input and "Random amplitude scale" for proprioceptive input are utilized to achieve state-of-the-art results are introduced here.
Reinforcement Learning - It is a machine learning training method based on rewarding desired behaviours and/or punishing undesired ones.
Augmented Data - Techniques used to increase the amount of data by adding slightly modified copies of already existing data or newly created synthetic data from existing data.
Augmentation Methods

- Crop: Extracts a random patch from the original frame.
- Translate: Random translation renders the full image within a larger frame and translates the image randomly across the larger frame.
- Window: Selects a random window from an image by masking out the cropped part of the image.
- Grayscale: Converts RGB images to grayscale with some random probability p.
- Cutout: Randomly inserts a small black occlusion into the frame, which may be perceived as cutting out a small patch from the originally rendered frame.
- Cutout-color: Another variant of cutout where instead of rendering black, the occlusion color is randomly generated.
- Flip: Flips an image at random across the vertical axis.
- Rotate: Randomly samples an angle and rotates the image accordingly.
- Random convolution: Augments the image color by passing the input observation through a random convolutional layer.
- Color jitter: Converts RGB image to HSV and adds noise to the HSV channels, which results in explicit color jittering.
Results
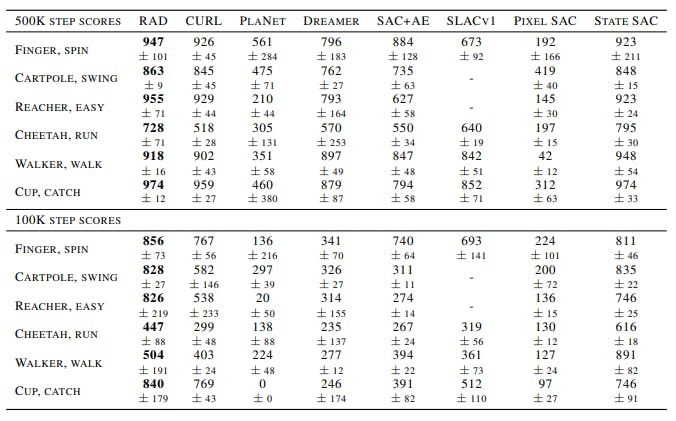
Now from the above results, it can be claimed that RAD is a very good technique for a model to understand the environment better on paper. So among all the augmentation technique according to researchers Cropping the inputs are the best ways to maximize the rewards. This can be more understood by the confusion matrix and attention plot below:
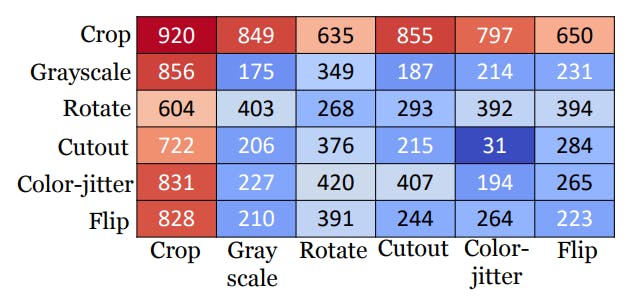
As shown above, when Crop x Crop is applied the score is maximum and in the below result it can be seen that while using the crop method the models attention is actually on the plane shown in yellow which makes sense as this plane needs to be balanced vertically to position the model right.

Conclusion
So just by applying random cropping can the RL model gain more rewards? Actually, according to the generalization scores shown in this paper, it can be stated that this only depends on the model environment that either the Cropping or augmentation will perform better or not.
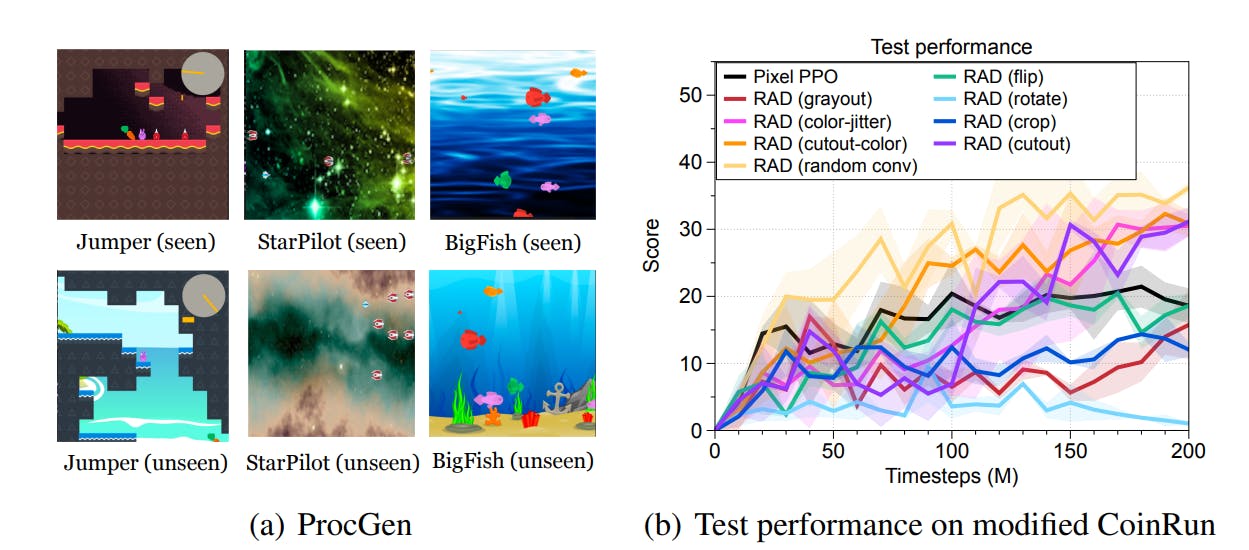
Now when generalized with OpenAI ProcGen environments shown above it gave a very doubtful conclusion
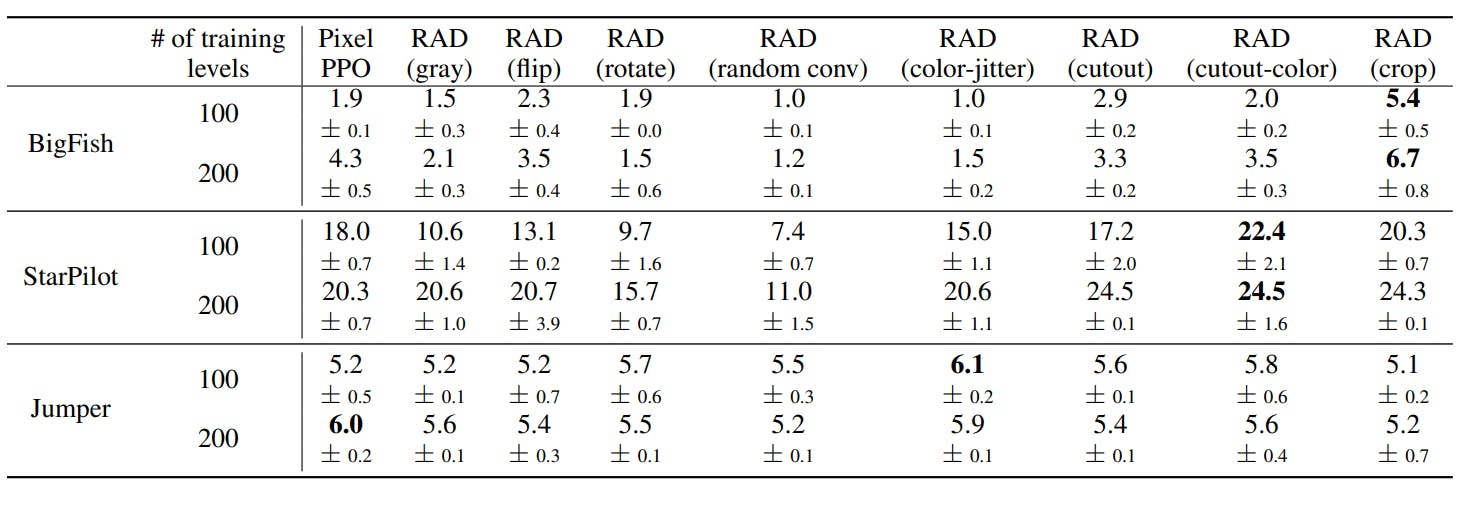 As the cropping method only performs well for BigFish env which outperforms Pixel PPO with a great lead-in both 100 and 200 levels of training but when it comes to StarPilot env the cropping method loses the position to the cutout-color method though the difference is small but it loses the lead again when applied to Jumper env
all the RAD techniques are suppressed by Pixel PPO. From this, it can be said that Data Augmentation might be considered when the environment doesn't have a major change as seen in StarPilot and BigFish where the difference was in the background but when the architecture of env is changed the RAD techniques must be used with caution as it might not perform that great.
As the cropping method only performs well for BigFish env which outperforms Pixel PPO with a great lead-in both 100 and 200 levels of training but when it comes to StarPilot env the cropping method loses the position to the cutout-color method though the difference is small but it loses the lead again when applied to Jumper env
all the RAD techniques are suppressed by Pixel PPO. From this, it can be said that Data Augmentation might be considered when the environment doesn't have a major change as seen in StarPilot and BigFish where the difference was in the background but when the architecture of env is changed the RAD techniques must be used with caution as it might not perform that great.